
NVIDIA T4 lleva aceleración por GPU a los servidores empresariales líderes en el mundo.
Las GPUs profesionales NVIDIA T4 y las librerías de aceleración CUDA-X preparan los Data Center para las diversas y complejas cargas de trabajo actuales que incluyen HPC Deep Learning tanto entrenamiento como inferencia, machine learning, data analytics, encoding y visualización gráfica. Con el soporte de la plataforma NGC (Nvidia GPU Cloud), los equipos de TI pueden construir infraestructuras de Data Center acelerados por GPU estándar con la mayoría de los fabricantes de servidores del mundo como ASUS Server.
Con respecto a la configuraciones clásica de CPU (Ver: Nota al pie) con NVIDIA T4 obtenemos:
- Hasta un 33% más de rendimiento en infraestructuras de escritorio virtual (VDI).
- Hasta 35x veces más rápido en Machine Learning.
- Hasta 10 veces más rápido en entrenamiento en Deep Learning.
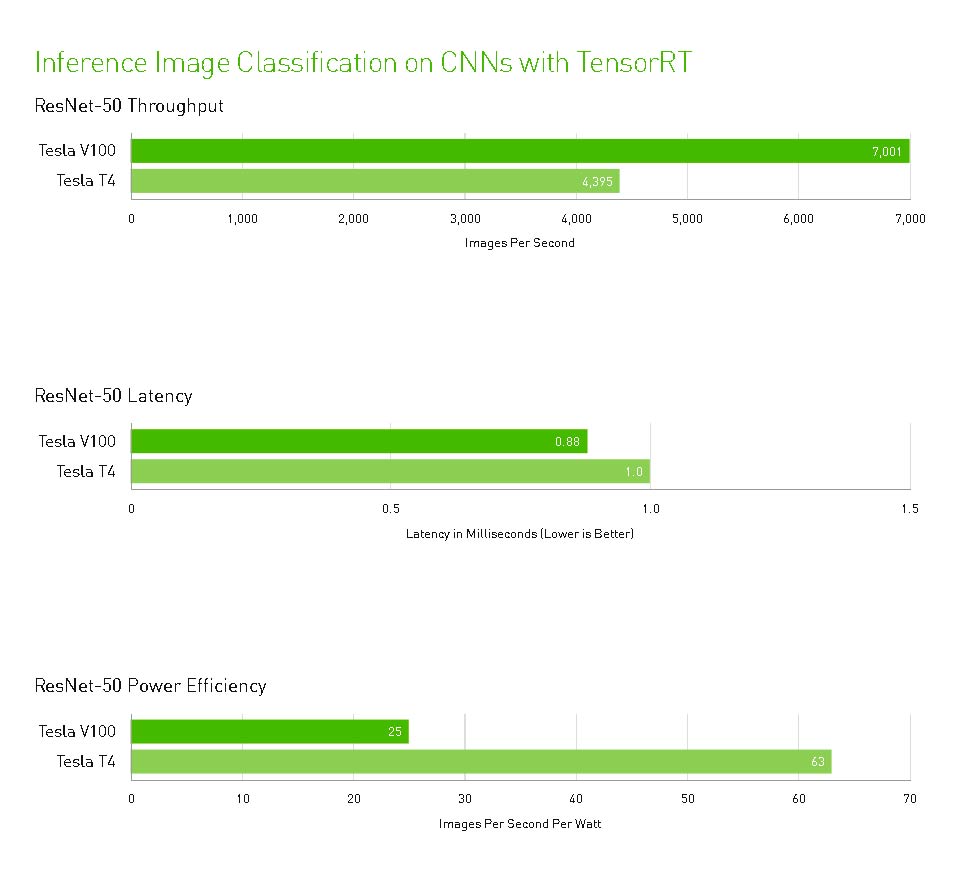
- Hasta 40 veces más rápido para obtener información sobre la inferencia de Deep Learning.
(Nota el pie de pagina)
Aceleración en Deep Learning
Si bien el Deep Learning ha llegado bastante recientemente al mercado de la IA, las compañías han estado utilizando el Deep Learning para recopilar información a partir de datos durante décadas. La GPU del centro de datos NVIDIA T4 puede acelerar estas técnicas de aprendizaje automático utilizando RAPIDS, un conjunto de bibliotecas de open source para la preparación de datos y Deep Learning en la GPU. Usando herramientas de desarrollo familiares como Python, una GPU T4 puede acelerar el aprendizaje de la máquina hasta 35X en comparación con un servidor solo para CPU, incluidos algoritmos como XGBoost, PCA, K-means, k-NN, DBScan y tSVD.
Los Tensor cores de Turing aceleran NVIDIA T4 en servidores profesionales.
NVIDIA T4 se basa en la revolucionaria tecnología Tensor Core de NVIDIA Turing ™ con computación de precisión múltiple para Workloads de AI. Al potenciar el rendimiento innovador de FP32 y FP16 a INT8, así como a INT4, T4 ofrece un rendimiento de inferencia hasta 40 veces mayor que las CPU, para capacitación, un solo servidor con dos GPU T4 reemplaza nueve servidores de CPU de doble socket.
Los desarrolladores pueden utilizar los Tensor Core de Turing directamente a través de las bibliotecas de software NVIDIA CUDA-X AI integrándose con todos los frameworks de AI. Construidas sobre CUDA, el modelo de programación paralelo de NVIDIA, las librerías CUDA-X proporcionan optimizaciones para los requisitos informáticos específicos de inteligencia artificial, máquinas autónomas, computación de alto rendimiento y gráficos.
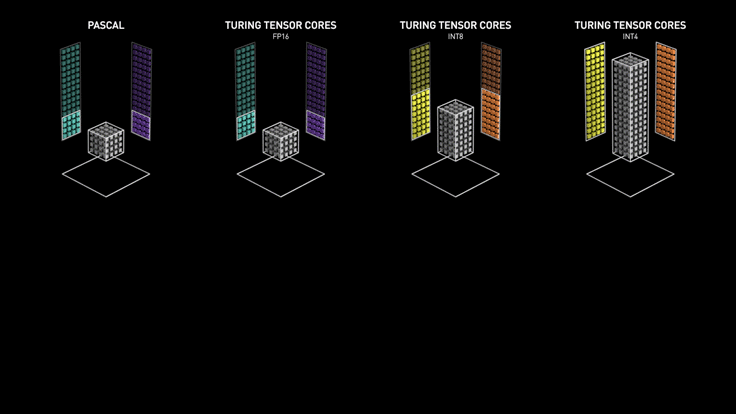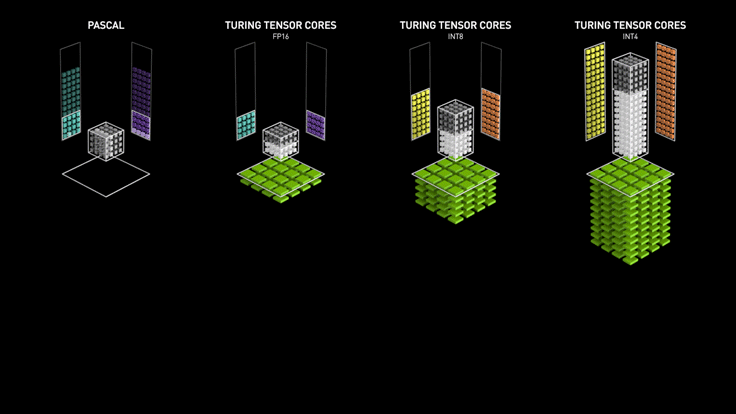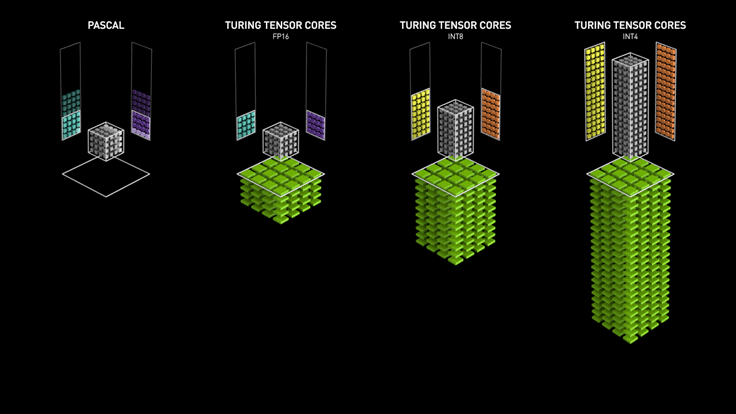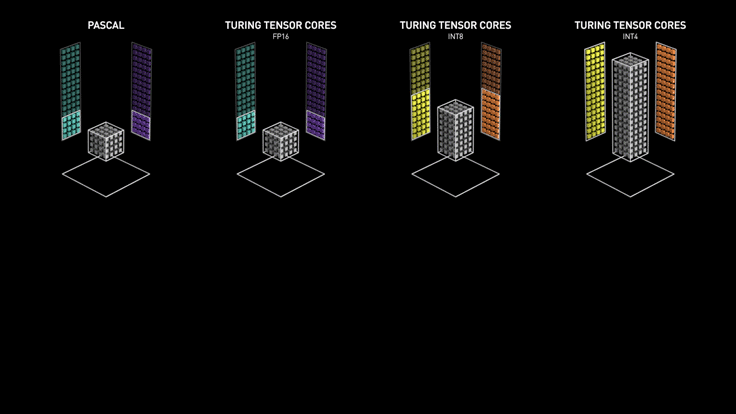
Experiencias excepcionales de VDI con NVIDIA T4
Los servidores principales equipados con NVIDIA T4 están certificados por nuestros socios para el software de GPU virtual, lo que garantiza que los usuarios disfruten de experiencias de escritorio virtual de alta calidad desde cualquier lugar y en cualquier dispositivo. Desde trabajadores y profesionales móviles hasta diseñadores e ingenieros, NVIDIA T4 combinada con el software virtual de NVIDIA GPU – NVIDIA GRID® Virtual PC (GRID vPC) y NVIDIA Quadro® Virtual Data Center Workstation (Quadro vDWS), puede acelerar la experiencia VDI, ofreciendo hasta un 33 % de mejora de rendimiento que los entornos VDI solo para CPU.
Los servidores profesionales están preparados para NGC
Los contenedores NGC están preconstruidos y altamente optimizados para la computación de GPU. Ofrecen la experiencia incomparable de NVIDIA y el apoyo al ecosistema para los frameworks de Deep Learning, el software RAPIDS, NVIDIA TensorRT ™ y más de 600 aplicaciones informáticas de alto rendimiento. NGC de NVIDIA permite a todos los fabricantes de servidores validar los contenedores NGC en sus plataformas para brindar a los administradores de Data Center la confianza para implementar despliegues hyper-escalables y elásticos de su infraestructura.
INFERENCIA TIEMPO REAL
La capacidad de respuesta es clave para la participación del usuario en servicios tales como inteligencia artificial conversacional, sistemas de recomendación y búsqueda visual. A medida que los modelos aumentan en precisión y complejidad, entregar la respuesta correcta en el momento requiere una capacidad de cómputo exponencialmente mayor. T4 ofrece hasta 40 veces más rendimiento, por lo que se pueden atender más solicitudes en tiempo real.

Rendimiento de transcodificación de video
A medida que el volumen de los videos online continúa creciendo exponencialmente, la demanda de soluciones para buscar de manera eficiente y obtener información del video también continúa creciendo. Tesla T4 ofrece un rendimiento innovador para aplicaciones de video AI, con motores de transcodificación de hardware dedicados que ofrecen el doble de rendimiento de decodificación que las GPU de generaciones anteriores. T4 puede decodificar hasta 38 streams de video en HD total, lo que facilita la integración del aprendizaje profundo escalable en los canales de video para ofrecer servicios de video innovadores e inteligentes.

NVIDIA Tesla T4 Specifications
Performance
- Turing Tensor Cores: 320
- NVIDIA CUDA® cores: 2,560
- Single Precision Performance (FP32):8.1 TFLOPS
- Mixed Precision (FP16/FP32): 65 FP16 TFLOPS
- INT8 Precision: 130 INT8 TOPS
- INT4 Precision: 260 INT4 TOPS
- Interconnect: Gen3 – x16 PCIe
Memory:
- Capacity:16 GB GDDR6
- Bandwidth: 320+ GB/s
Power: 70 watts
VDI: GRID vPC probado en un servidor con 2x Intel Xeon Gold 6148 (20c, 2.4 GHz), GRID vPC con T4-1B (64 VM), VMware ESXi 6.7, NVIDIA vGPU Software (410.91 / 412.16), Windows 10 (1803) , 2 vCPU, 4 GB de RAM, resolución 1920×1080, monitor único, VMware Horizon 7.6 La experiencia del usuario se midió utilizando una herramienta de evaluación comparativa interna de NVIDIA que mide marcos remotos que ejecutan aplicaciones de productividad de oficina como Microsoft PowerPoint, Word, Excel, Chrome, visualización de PDF y video reproducción.
Machine Learning: nodos de la CPU (61 GB de memoria, 8 vCPU, plataforma de 64 bits), Apache Spark. Conjunto de datos CSV de 200 GB; La preparación de datos incluye uniones, transformaciones variables. Configuración del servidor GPU: Dual-Socket Xeon E5-2698 v4@3.6GHz, 20 GPU T4 en 5 nodos, cada uno con 4 GPU T4. Todos se ejecutan en la red InfiniBand, los datos de la CPU para XGBoost y los pasos de conversión de datos se estiman en base a los datos medidos para 20 nodos de la CPU, y reducen el tiempo de ejecución en un 60% para normalizar la capacitación en un conjunto de datos más pequeño en T4.
Deep Learning Training and Inference: GPU: Dual-Socket Xeon E5-2698 v4@3.6GHz. Servidores GPU: 2xT4s para entrenamiento, 1xT4 para inferencia, contenedor NGC 18.11-py3 con CUDA 10.0.130; NCCL 2.3.7, cuDNN 7.4.1.5; cuBLAS 10.0.130 | Controlador NVIDIA: 384.145.