¿Qué es la computación de alto rendimiento (HPC)?
La computación de alto rendimiento (HPC – High Performance Computing) es la capacidad de procesar datos y realizar cálculos complejos a gran velocidad utilizando varios ordenadores y dispositivos de almacenamiento.
Comparativamente, un equipo de sobremesa con un procesador de 3 GHz puede realizar unos 3.000 millones de cálculos por segundo, mientras que, con las soluciones HPC, se pueden realizar cuatrillones de cálculos por segundo.

De esta forma, un servidor para HPC es capaz de resolver algunos de los principales problemas en el mundo de la ciencia, la ingeniería y los negocios mediante simulaciones, modelos y análisis. Algunos ejemplos son: el descubrimiento de nuevos componentes de medicamentos para combatir enfermedades como el cáncer, la simulación de dinámicas moleculares para la creación de nuevos materiales o el pronóstico de cambios climáticos.
Los tipos de soluciones HPC más conocidos son:
- Computación paralela. Es un conjunto de sistemas simples con varios procesadores trabajando simultáneamente sobre la misma tarea.
- Computación distribuida. Es una red de ordenadores conectados que funcionan de manera colaborativa para realizar diferentes tareas.
- Computación en malla o Grid. Es un sistema de computación distribuida que coordina computadoras de diferente hardware y software para procesar una tarea con gran cantidad de recursos y poder de procesamiento.
¿Cómo funciona la HPC?
Para procesar la información en HPC, existen dos métodos principales: el procesamiento en serie y el procesamiento en paralelo. Veamos cada uno de ellos.
Procesamiento en serie
Es el que realizan las unidades de procesamiento central (CPU). Estas dividen una gran carga de trabajo compartida en tareas más pequeñas que se comunican continuamente. Cada núcleo de CPU realiza solo una tarea a la vez. Una de las funciones del procesamiento en serie es la ejecución de aplicaciones básicas como el procesamiento de textos.
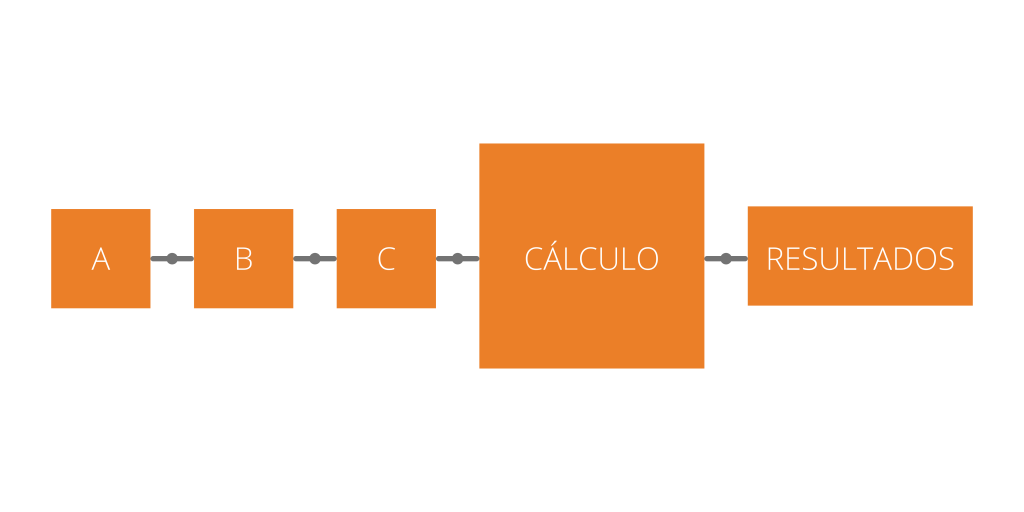
Procesamiento en paralelo
Es el que realizan la unidades de procesamiento gráfico (GPU). Estas son capaces de realizar diferentes operaciones aritméticas de forma simultánea por medio de una matriz de datos. Las cargas de trabajo paralelas son problemas de computación divididos en tareas sencillas e independientes que se pueden ejecutar a la vez sin apenas comunicaciones entre ellas. Una de las funciones del procesamiento en paralelo es la ejecución de aplicaciones de aprendizaje automático (Machine Learning), como el reconocimiento de objetos en vídeos.
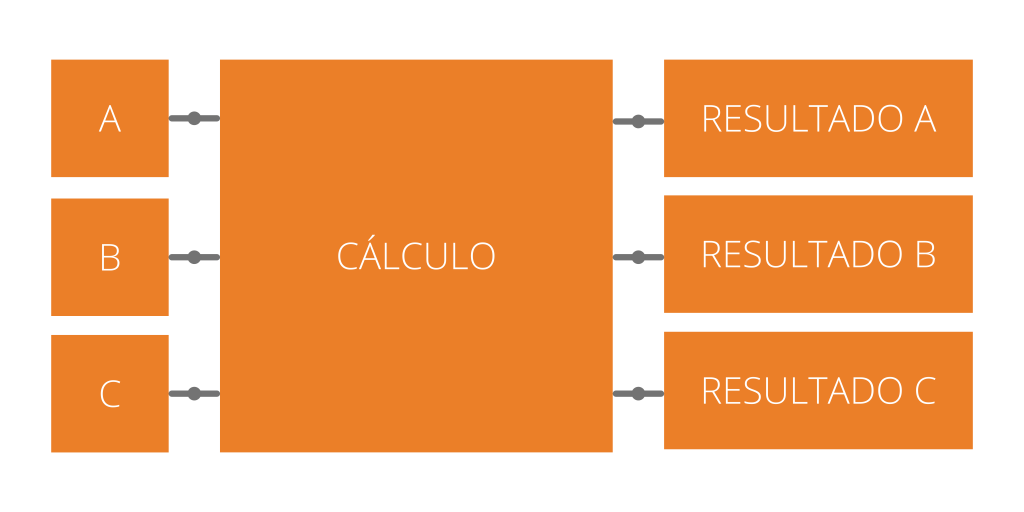
El futuro de la HPC
Cada vez más empresas e instituciones están recurriendo a la HPC. Como resultado, se prevé que el mercado de este tipo de servidores crezca hasta los 50.000 millones de dólares en 2023. Además, gran parte de ese crecimiento se verá reflejado en la implementación de la HPC en la nube, que reduce de forma considerable los costes de una empresa al no ser necesaria la inversión en infraestructuras de centros de datos.
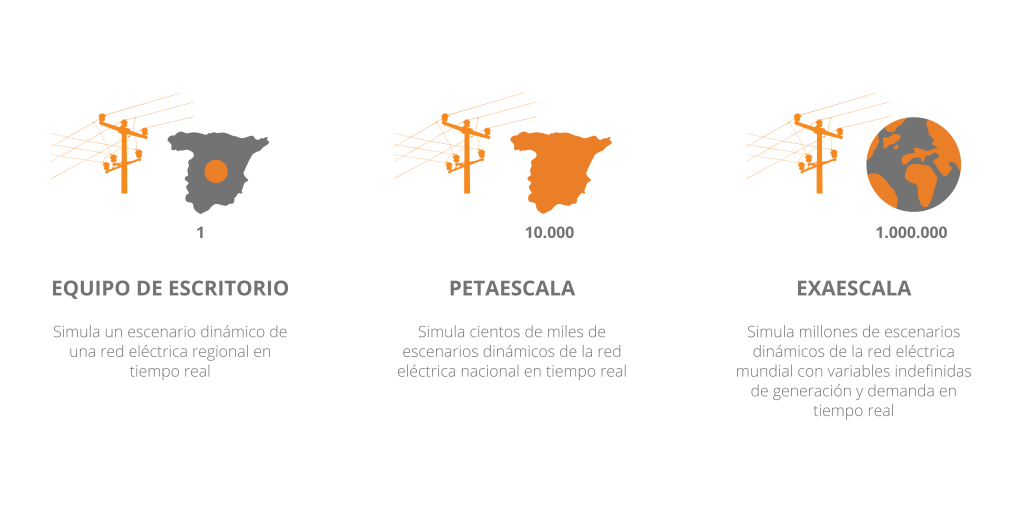
De igual forma, gracias a los avances tecnológicos tanto en procesamiento como en rendimiento, pronto se dará un nuevo paso en la era de la supercomputación: la exaescala, con la que se podrán realizar 10^18 (1.000.000.000.000.000.000) operaciones por segundo.
HPC en Azken Muga
Finalmente, incorporando la tecnología más avanzada en proceso, conectividad y almacenamiento, los servidores de Azken Muga satisfacen las necesidades de sus clientes, que buscan acelerar sus resultados de negocio con una infraestructura optimizada y realizar sus tareas de manera más rápida, fiable y asequible.
Soluciones
NG10 Dual Xeon SP3-12B

Es un superordenador en formato rack 4U de doble zócalo que admite hasta diez tarjetas GPU de alto rendimiento. Con dos procesadores Intel Xeon Scalable de tercera generación y 32 módulos DIMM DDR4, proporcionando una extraordinaria potencia de cálculo heterogénea para una gran variedad de aplicaciones de computación científica de alto rendimiento basadas en la GPU, entrenamiento de IA, inferencia y aprendizaje profundo. Un servidor concebido para balancear mas de 190 TeraFlops en doble precisión. La mejor combinación de proceso CPU, almacenamiento y proceso paralelo sobre GPU, una arquitectura ideal que alberga hasta 10 GPUs NVIDIA® de última generación.
NG8 Dual Epyc 9004 8-B

Servidor en formato rack de 4U con procesadores AMD EPYC™ 9004 series dual socket, hasta 192 núcleos Zen 4, 12 canales por socket de memoria RAM DDR5 y con el mayor rendimiento de conmutación con PCIe 5.0. Diseñado para las demandas de la infraestructura de IA empresarial, ofreciendo un rendimiento sin precedentes con GPU´s líderes del segmento, una interconexión de GPU más rápida, un mayor ancho de banda, la cual admite una configuración escalable de hasta ocho GPU´s de doble slot con la opción de NVIDIA NVLink® Bridge o AMD Infinity Fabric™ Link para permitir el escalado del rendimiento, lo que permite adaptarse a sus cargas de trabajo de IA y HPC.
GLOSARIO
- Supercomputadora: el tope de gama en HPC, según la evolución de los estándares de rendimiento.
- Computación heterogénea: arquitectura de HPC que optimiza las capacidades de procesamiento en serie (CPU) y en paralelo (GPU).
- Memoria: donde se almacenan los datos en un sistema HPC para acceder a ellos rápidamente.
- Petaescala: supercomputadora diseñada para realizar mil billones (10^15) de cálculos por segundo.
- Exaescala: supercomputadora diseñada para realizar un trillón (10^18) de cálculos por segundo.
- FLOPS: unidades de potencia de procesamiento de las computadoras (operaciones de punto flotante por segundo). “FLOPS” describe una velocidad de procesamiento teórica: para hacer posible esa velocidad es necesario enviar datos a los procesadores de forma continua. Por lo tanto, el procesamiento de los datos se debe tener en cuenta en el diseño del sistema. La memoria del sistema, junto con las interconexiones que unen los nodos de procesamiento entre sí, impactan en la rapidez con la que los datos llegan a los procesadores.