Las librerías de procesamiento de datos NVIDIA CUDA-X se integrarán en las soluciones de inteligencia artificial de Azken para acelerar las tareas de preparación y procesamiento de datos que constituyen la base del desarrollo de la inteligencia artificial generativa.
Basadas en la plataforma de cálculo NVIDIA CUDA, las librerías CUDA-X aceleran el procesamiento de una amplia variedad de tipos de datos, lo que incluye tablas, texto, imágenes y vídeo. Entre ellas se incluye la librería NVIDIA RAPIDS cuDF, que acelera hasta 110 veces el trabajo de los casi 10 millones de científicos de datos que utilizan el software pandas utilizando una GPU NVIDIA RTX 6000 Ada Generation en lugar de un sistema basado únicamente en CPU, sin necesidad de modificar el código.
«Pandas es la herramienta esencial de millones de científicos de datos que procesan y preparan datos para la IA generativa. Acelerar Pandas sin cambiar el código será un gran paso adelante. Los científicos de datos podrán procesarlos en minutos en lugar de en horas, y manejar órdenes de grandes magnitudes de datos para entrenar modelos de IA generativa».
Jensen Huang, fundador y CEO de NVIDIA.
Fuente: NVIDIA
Pandas proporciona una potente estructura de datos, denominada DataFrames, que permite a los desarrolladores manipular, limpiar y analizar fácilmente datos tabulares. La librería NVIDIA RAPIDS cuDF acelera pandas para que pueda ejecutarse en las GPU sin necesidad de modificar el código, en lugar de depender de las CPU, que pueden ralentizar las cargas de trabajo a medida que aumenta el tamaño de los datos. RAPIDS cuDF es compatible con librerías de terceros y unifica los flujos de trabajo de GPU y CPU para que los científicos de datos puedan desarrollar, probar y ejecutar modelos en producción sin problemas.
Se espera que NVIDIA RAPIDS cuDF para acelerar pandas sin cambiar el código esté disponible en las soluciones de estaciones de trabajo de IA de Azken con GPU NVIDIA RTX y GeForce RTX próximamente.
AWS será el primer proveedor de cloud computing en ofrecer los superchips NVIDIA GH200 Grace Hopper. Interconectados con la tecnología NVIDIA NVLink a través de NVIDIA DGX Cloud se ejecutarán en Amazon Elastic Compute Cloud (Amazon EC2).
Se trata de una tecnología revolucionaria para la computación en la nube.
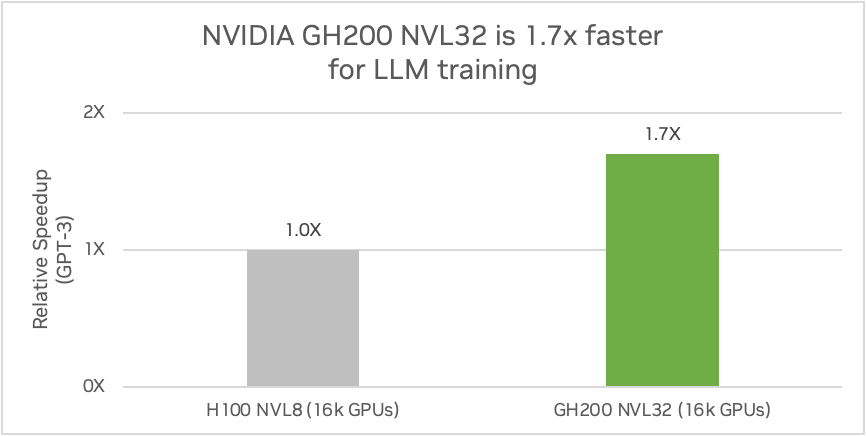
NVIDIA GH200 NVL32 es una solución de rack escalable dentro de NVIDIA DGX Cloud o en las infraestructuras de Amazon. Cuenta con un dominio NVIDIA NVLink de 32 GPU y una enorme memoria unificada de 19,5 TB. Superando las limitaciones de memoria de un único sistema, es 1,7 veces más rápida para el entrenamiento GPT-3 y 2 veces más rápida para la inferencia de modelos de lenguaje de gran tamaño (LLM) en comparación con NVIDIA HGX H100.
Las infraestructuras de AWS equipadas con NVIDIA GH200 Grace Hopper Superchip contarán con 4,5 TB de memoria HBM3e. Esto supone un aumento de 7,2 veces en comparación con las EC2 P5 equipadas con NVIDIA H100. Esto permite a los desarrolladores ejecutar modelos de mayor tamaño y mejorar el rendimiento del entrenamiento.
Además, la interconexión de memoria de la CPU a la GPU es de 900 GB/s, 7 veces más rápida que PCIe Gen 5. Las GPU acceden a la memoria de la CPU de forma coherente con la caché, lo que amplía la memoria total disponible para las aplicaciones. Este es el primer uso del diseño escalable GH200 NVL32 de NVIDIA. Un diseño de referencia modular para supercomputación, centros de datos e infraestructuras en la nube. Proporciona una arquitectura común para las configuraciones de procesadores GH200 y sucesores.
En este artículo se explica la infraestructura que lo hace posible y se incluyen algunas aplicaciones representativas.
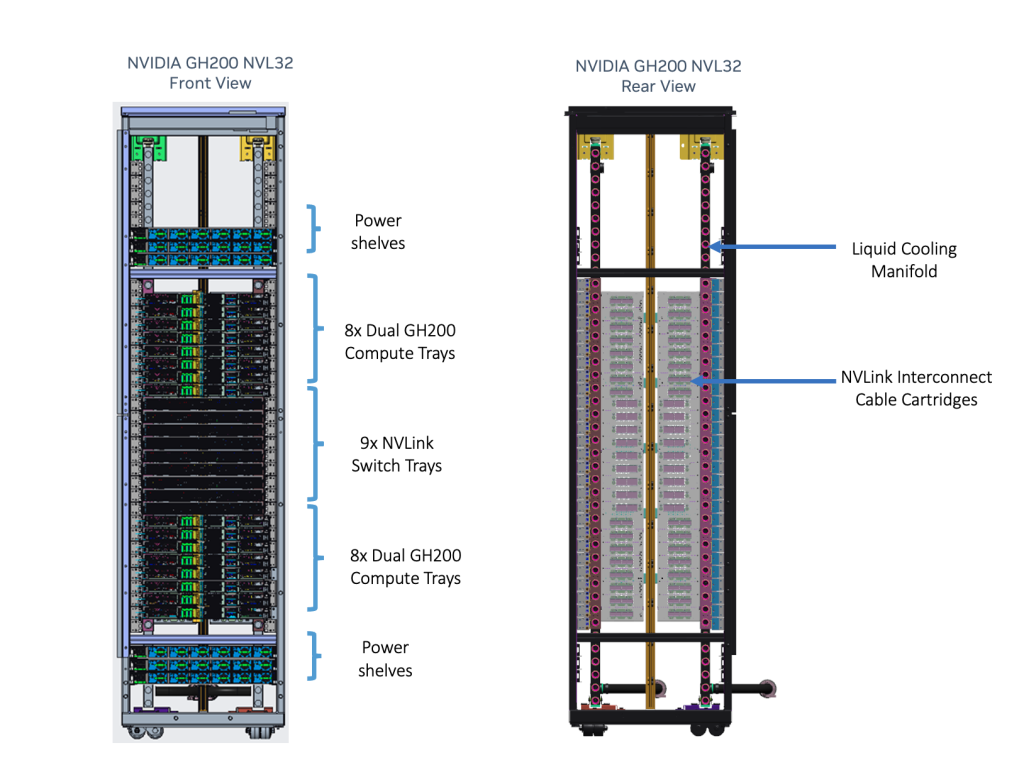
NVIDIA GH200 NVL32
NVIDIA GH200 NVL32 es un modelo de rack para los superchips NVIDIA GH200 Grace Hopper conectados a través de NVLink destinado a centros de datos de hiperescala. Admite 16 nodos de servidor Grace Hopper duales compatibles con el diseño de chasis NVIDIA MGX. Admite refrigeración líquida para maximizar la densidad y la eficiencia del cálculo.
NVIDIA GH200 NVL32 es una solución a escala de rack que ofrece un dominio NVLink de 32 GPU y 19,5 TB de memoria unificada. Fuente: NVIDIA
NVIDIA GH200 Grace Hopper Superchip con un NVLink-C2C coherente crea un espacio de direcciones de memoria direccionable NVLink para simplificar la programación de modelos. Combina memoria de sistema de gran ancho de banda y bajo consumo, LPDDR5X y HBM3e, para aprovechar al máximo la aceleración de la GPU NVIDIA y los núcleos Arm de alto rendimiento en un sistema bien equilibrado.
Los nodos del servidor GH200 están conectados con un cartucho de cable de cobre pasivo NVLink para permitir que cada GPU Hopper acceda a la memoria de cualquier otro Superchip Grace Hopper de la red. Lo que proporciona 32 x 624 GB, o 19,5 TB de memoria direccionable NVLink.
Esta actualización del sistema de conmutación NVLink utiliza la interconexión de cobre NVLink para conectar 32 GPU GH200 mediante nueve conmutadores NVLink que incorporan chips NVSwitch de tercera generación. El sistema de conmutación NVLink implementa una red fat-tree totalmente conectada para todas las GPU del cluster. Para necesidades de mayor escala, el escalado con InfiniBand o Ethernet a 400 Gb/s proporciona un rendimiento increíble y una solución de supercomputación de IA de bajo consumo energético.
NVIDIA GH200 NVL32 es compatible con el SDK HPC de NVIDIA y el conjunto completo de librerías CUDA, NVIDIA CUDA-X y NVIDIA Magnum IO. Lo que permite acelerar más de 3.000 aplicaciones de GPU.
Casos de uso y resultados de rendimiento
NVIDIA GH200 NVL32 es ideal para el entrenamiento y la inferencia de la IA, los sistemas de recomendación, las redes neuronales de grafos (GNN), las bases de datos vectoriales y los modelos de generación aumentada por recuperación (RAG), como se detalla a continuación.
Entrenamiento e inferencia de IA
La IA generativa ha irrumpido con fuerza en todo el mundo, como demuestran las revolucionarias capacidades de servicios como ChatGPT. LLMs como GPT-3 y GPT-4 están permitiendo la integración de capacidades de IA en todos los productos de todas las industrias, y su tasa de adopción es asombrosa.
ChatGPT se convirtió en la aplicación que más rápido alcanzó los 100 millones de usuarios, logrando ese hito en sólo 2 meses. La demanda de aplicaciones de IA generativa es inmensa y crece exponencialmente.
Un centro de datos Ethernet con 16.000 GPUs que utilice NVIDIA GH200 NVL32 ofrecerá 1,7 veces más rendimiento que uno compuesto por H100 NVL8, que es un servidor NVIDIA HGX H100 con ocho GPUs H100 conectadas mediante NVLink. (Estimaciones preliminares de rendimiento sujetas a cambios). Fuente: NVIDIA
Los LLM requieren un entrenamiento a gran escala y multi-GPU. Los requisitos de memoria para GPT-175B serían de 700 GB, ya que cada parámetro necesita cuatro bytes (FP32). Se utiliza una combinación de paralelismo de modelos y comunicaciones rápidas para evitar quedarse sin memoria con GPU de memoria más pequeña.
NVIDIA GH200 NVL32 está diseñada para la inferencia y el entrenamiento de la próxima generación de LLM. Al superar los cuellos de botella de memoria, comunicaciones y cálculo con 32 superchips Grace Hopper GH200 conectados por NVLink, el sistema puede entrenar un modelo de un billón de parámetros 1,7 veces más rápido que NVIDIA HGX H100.
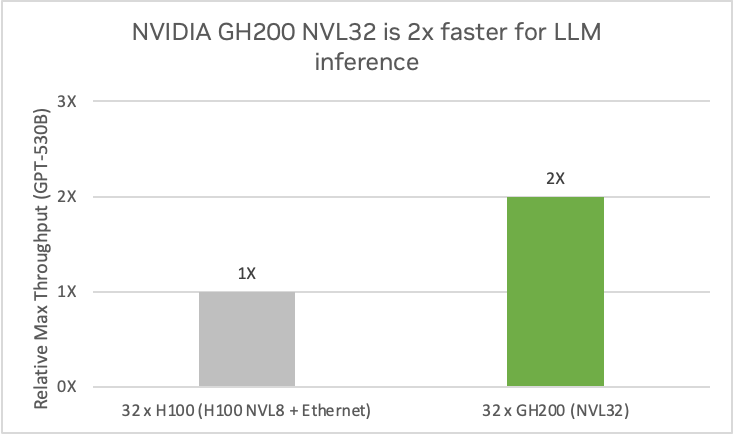
NVIDIA GH200 NVL32 muestra un rendimiento de inferencia de modelos GPT-3 530B 2x más rápido en comparación con H100 NVL8 con 80 GB de memoria GPU. (Estimaciones preliminares de rendimiento sujetas a cambios). Fuente: NVIDIA
El sistema NVIDIA GH200 NVL32 multiplica por 2 el rendimiento de cuatro sistemas H100 NVL8 con un modelo de inferencia GPT-530B. El gran espacio de memoria también mejora la eficiencia operativa, ya que permite almacenar varios modelos en el mismo nodo e intercambiarlos rápidamente para maximizar su utilización.
Sistemas de recomendación
Los sistemas de recomendación son el motor del Internet personalizado. Se utilizan en comercio electrónico y minorista, medios de comunicación y redes sociales, anuncios digitales, etc. para personalizar contenidos. Esto genera ingresos y valor empresarial. Los recomendadores utilizan incrustaciones que representan a los usuarios, los productos, las categorías y el contexto, y pueden tener un tamaño de hasta decenas de terabytes.
Un sistema de recomendación muy preciso proporcionará una experiencia de usuario más atractiva, pero también requiere una incrustación mayor. Las incrustaciones tienen características únicas para los modelos de IA, ya que requieren grandes cantidades de memoria con un gran ancho de banda y una conexión en red ultrarrápida.
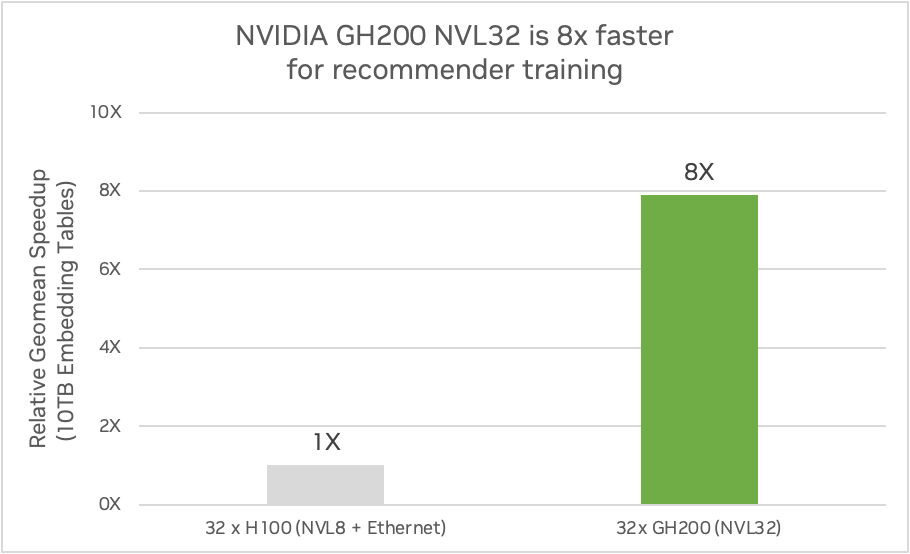
NVIDIA GH200 NVL32 con Grace Hopper proporciona 7 veces más cantidad de memoria de acceso rápido en comparación con cuatro HGX H100 y proporciona 7 veces más ancho de banda en comparación con las conexiones PCIe Gen5 a la GPU en diseños convencionales basados en x86. Permite incrustaciones 7 veces más detalladas en comparación con las H100 con x86.
También puede proporcionar hasta 7,9 veces más rendimiento de entrenamiento para modelos con tablas de incrustación masivas. La siguiente figura muestra una comparación de un sistema GH200 NVL32 con 144 GB de memoria HBM3e e interconexión NVLink de 32 vías frente a cuatro servidores HGX H100 con 80 GB de memoria HBM3 conectados con interconexión NVLink de 8 vías utilizando un modelo DLRM. Las comparaciones se realizaron entre los sistemas GH200 y H100 utilizando tablas de incrustación de 10 TB y utilizando tablas de incrustación de 2 TB.
Comparación de un sistema NVIDIA GH200 NVL32 con cuatro servidores HGX H100 en la formación de recomendadores. (Estimaciones preliminares de rendimiento sujetas a cambios). Fuente: NVIDIA
Redes neuronales gráficas
Las GNN (Graph Neural Networks) aplican el poder predictivo del aprendizaje profundo a ricas estructuras de datos que representan objetos y sus relaciones como puntos conectados por líneas en un gráfico. Muchas ramas de la ciencia y la industria ya almacenan datos valiosos en bases de datos de gráficos.
El aprendizaje profundo se utiliza para entrenar modelos predictivos que descubren nuevas perspectivas a partir de gráficos. Cada vez son más las organizaciones que aplican las GNN para mejorar el descubrimiento de fármacos, la detección de fraudes, la infografía, la ciberseguridad, la genómica, la ciencia de los materiales y los sistemas de recomendación. En la actualidad, los gráficos más complejos procesados por GNN tienen miles de millones de nodos, billones de aristas y funciones repartidas entre nodos y aristas.
NVIDIA GH200 NVL32 proporciona memoria masiva de CPU-GPU para almacenar estas complejas estructuras de datos y acelerar el cálculo. Además, los algoritmos de gráficos a menudo requieren accesos aleatorios a estos grandes conjuntos de datos que almacenan las propiedades de los vértices.
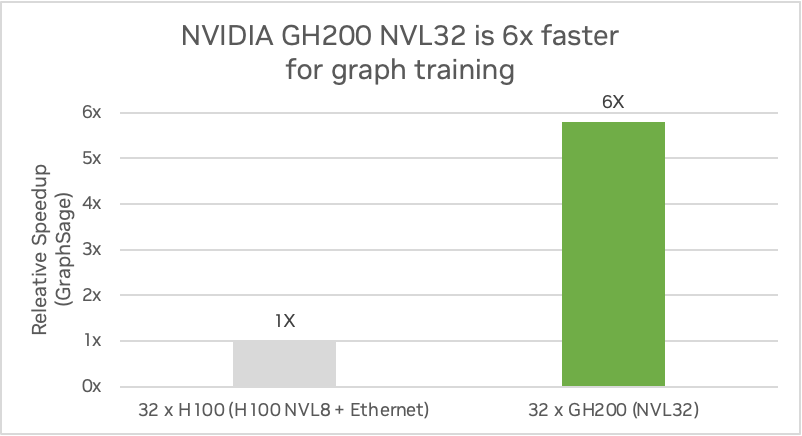
Estos accesos suelen verse limitados por el ancho de banda de las comunicaciones entre nodos. La conectividad GPU-GPU NVLink de NVIDIA GH200 NVL32 proporciona una enorme aceleración de estos accesos aleatorios. GH200 NVL32 puede aumentar el rendimiento de entrenamiento de GNN hasta 5,8 veces en comparación con NVIDIA H100.
La siguiente figura muestra una comparación de un sistema GH200 NVL32 con 144 GB de memoria HBM3e e interconexión NVLink de 32 vías frente a cuatro servidores HGX H100 con 80 GB de memoria HBM3 conectados con interconexión NVLink de 8 vías utilizando GraphSAGE. GraphSAGE es un marco inductivo general para generar de forma eficiente incrustaciones de nodos para datos no vistos previamente.
Comparación de un sistema NVIDIA GH200 NVL32 con cuatro servidores HGX H100 en el entrenamiento de gráficos. (Estimaciones preliminares de rendimiento sujetas a cambios). Fuente: NVIDIA
Resumen
Amazon y NVIDIA han anunciado la llegada de NVIDIA DGX Cloud a AWS. AWS será el primer proveedor de servicios en la nube en ofrecer NVIDIA GH200 NVL32 en DGX Cloud y como instancia EC2. La solución NVIDIA GH200 NVL32 cuenta con un dominio NVLink de 32 GPU y 19,5 TB de memoria unificada. Esta configuración supera con creces a los modelos anteriores en el entrenamiento GPT-3 y la inferencia LLM.
La interconexión de memoria CPU-GPU de la NVIDIA GH200 NVL32 es extraordinariamente rápida, lo que mejora la disponibilidad de memoria para las aplicaciones. Esta tecnología forma parte de un modelo escalable para centros de datos de hiperescala, respaldado por un completo paquete de software y librerías de NVIDIA, que acelera miles de aplicaciones de GPU. NVIDIA GH200 NVL32 es ideal para tareas como el entrenamiento y la inferencia de LLM, los sistemas de recomendación y las GNN, entre otras, ya que ofrece mejoras significativas del rendimiento de las aplicaciones de IA y computación.
Universal Scene Description (USD) es un marco y ecosistema extensible diseñado para describir, componer, simular y colaborar en entornos tridimensionales.
Inicialmente desarrollado por Pixar Animation Studios, USD, también conocido como OpenUSD, supera la noción de ser simplemente un formato de archivo. Se trata de una descripción de escenas 3D de código abierto, que se emplea en la creación e intercambio de contenido 3D entre diversas herramientas.
Su asombroso poder y versatilidad lo han erigido en un estándar de la industria, no solo en la comunidad de efectos visuales, sino también en ámbitos como la arquitectura, el diseño, la robótica, la manufactura y otras disciplinas.
USD en NVIDIA
USD constituye el fundamento de NVIDIA Omniverse, una plataforma de cómputo componible que facilita la creación de flujos de trabajo y aplicaciones 3D basadas en USD. Omniverse conecta una amplia gama de herramientas de creación de contenido entre sí y con la tecnología de trazado de rayos NVIDIA RTX en tiempo real.
NVIDIA ha expandido este ecosistema mediante el desarrollo de nuevas herramientas, la integración de tecnologías y la provisión de ejemplos y tutoriales. Esta labor incluye la colaboración con un ecosistema de socios, entre ellos Pixar, Adobe, Apple y Autodesk, con el propósito de evolucionar USD hasta convertirlo en uno de los componentes esenciales y en el lenguaje predominante del metaverso.
Esta demo técnica muestra la potencia de la tecnología RTX en la plataforma Omniverse. Ha sido creada por un equipo de artistas y desarrolladores de NVIDIA Omniverse utilizando activos de USD, junto con trazado de rayos en tiempo real. El resultado es una simulación interactiva basada en la física con los coches RC más realistas jamás renderizados. Fuente: NVIDIA.
Explora las bibliotecas y herramientas preconstruidas de USD
Prueba USDView desde el Lanzador de Omniverse
USDView, desarrollado por Pixar, se presenta como una herramienta valiosa para cargar, visualizar e inspeccionar archivos OpenUSD.
Esta aplicación resulta una de las maneras más eficaces de adentrarse en la comprensión de Universal Scene Description. NVIDIA facilita USDView ya preconstruido y configurado para comenzar sin demora.
Descarga USDView y consulta la documentación para ampliar tus conocimientos.
Descarga las bibliotecas y herramientas preconstruidas de USD
Las bibliotecas USD solo están disponibles en forma de código fuente a través de Pixar. Con el fin de simplificar este proceso, NVIDIA ofrece bibliotecas preconstruidas junto con el conjunto de herramientas USD para su descarga. Este paquete brinda al usuario el apoyo necesario para iniciar el desarrollo de herramientas que aprovechen las ventajas de USD.
Descarga el paquete Python usd-core en PyPI
El paquete usd-core también está a tu disposición si lo que deseas experimentar con la API de Python o si únicamente requieres las funciones esenciales de USD para la lectura y escritura de etapas y capas.
USD viene preconstruido y solo es necesario ejecutar «pip install» para disponer de él.
Crea con MDL en Universal Scene Description
Universal Scene Description no establece preferencias en cuanto a la representación de propiedades de materiales. NVIDIA se esfuerza por permitir que los artistas desarrollen materiales destinados a una renderización de calidad cinematográfica, mediante un proceso automatizado que genera sombreadores más simples, pero que conservan su alta calidad en tiempo real.
Fuente: NVIDIA
Con este propósito, NVIDIA ha diseñado un Lenguaje de Definición de Materiales (MDL) de código abierto y compatible con las GPU, complementado por un destilador que simplifica los sombreadores para aplicaciones de vista previa y realidad virtual (VR). El SDK de MDL de NVIDIA ha sido adoptado por varios desarrolladores de aplicaciones, entre ellos Adobe, ChaosGroup y Unreal Engine de Epic.
Para potenciar los flujos de trabajo basados en MDL, NVIDIA también ha creado una especificación para hacer referencia a MDL en USD y ha desarrollado complementos para Omniverse.
En el arranque de la GTC sep22, Jensen Huang desvela los avances de la comprensión del lenguaje natural, el metaverso, los juegos y las tecnologías de IA que afectan a sectores que van desde el transporte y la sanidad hasta las finanzas y el entretenimiento.
Los nuevos servicios en la nube para apoyar los flujos de trabajo de IA y el lanzamiento de una nueva generación de GPU GeForce RTX. Estos han sido los protagonistas de la conferencia magistral de la GTC sep22 de NVIDIA; que ha estado repleta de nuevos sistemas y softwares.
La computación está avanzando a velocidades increíbles. El motor que impulsa este cohete es la computación acelerada y su combustible es la IA.
Jensen Huang, CEO de NVIDIA.
Huang relacionó las nuevas tecnologías con nuevos productos y nuevas oportunidades; desde el aprovechamiento de la IA para deleitar a los jugadores con gráficos nunca vistos, hasta la construcción de campos de pruebas virtuales donde las mayores empresas del mundo puedan perfeccionar sus productos.
Las empresas obtendrán nuevas y potentes herramientas para aplicaciones de HPC con sistemas basados en la CPU Grace y el superchip Grace Hopper. Los jugadores y creadores obtendrán nuevos servidores OVX impulsados por las GPU Ada Lovelace L40 para centros de datos. Los investigadores y científicos informáticos obtendrán nuevas funciones de modelos de lenguaje de gran tamaño con el servicio NeMo de NVIDIA LLM. Y la industria automovilística recibe Thor, un nuevo cerebro con un asombroso rendimiento de 2.000 teraflops.
Huang destacó cómo importantes socios y clientes de una variedad de sectores están implementando las tecnologías de NVIDIA. Por ejemplo, Deloitte, la mayor empresa de servicios profesionales del mundo, va a ofrecer nuevos servicios basados en NVIDIA AI y NVIDIA Omniverse.
Un «salto cuántico» en esta GTC sep22: GPU GeForce RTX 40 series
Lo primero que se presentó en la GTC sep22 fue el lanzamiento de la nueva generación de GPU GeForce RTX Serie 40 con tecnología Ada, que Huang calificó de «salto cuántico» que allana el camino a los creadores de mundos totalmente simulados.
Fuente: NVIDIA
Huang presentó a su audiencia Racer RTX, una simulación totalmente interactiva y enteramente trazada por rayos, con toda la acción modelada físicamente.
Los avances de Ada incluyen un nuevo multiprocesador de flujo, un nuevo RT con el doble de rendimiento de intersección de rayos y triángulos y un nuevo Tensor Core con el motor de transformación Hopper FP8 y 1,4 petaflops de potencia de procesamiento tensorial.
Ada también presenta la última versión de la tecnología NVIDIA DLSS: DLSS 3. Que utiliza la IA para generar nuevos fotogramas comparándolos con los anteriores para entender cómo está cambiando una escena. El resultado: aumentar el rendimiento de los juegos hasta 4 veces con respecto al renderizado por fuerza bruta.
DLSS 3 ha recibido el apoyo de muchos de los principales desarrolladores de juegos del mundo, con más de 35 juegos y aplicaciones que han anunciado su compatibilidad.
DLSS 3 es uno de nuestros mayores inventos en materia de renderizado neuronal
Jensen Huang, CEO de NVIDIA.
Una nueva generación de GPU GeForce RTX
Esta tecnología ayuda a ofrecer 4 veces más rendimiento de procesamiento con la nueva GeForce RTX 4090 frente a su precursora, la RTX 3090 Ti. La nueva «campeona de los pesos pesados» tiene un precio inicial de 1.599 dólares y estará disponible el 12 de octubre.
Además, la nueva GeForce RTX 4080 se lanzará en noviembre con dos configuraciones:
La GeForce RTX 4080 de 16 GB, con un precio de 1.199 dólares, tiene 9.728 núcleos CUDA y 16 GB de memoria Micron GDDR6X de alta velocidad. Con DLSS 3, es dos veces más rápida en los juegos actuales que la GeForce RTX 3080 Ti, y más potente que la GeForce RTX 3090 Ti a menor potencia.
La GeForce RTX 4080 12GB tiene 7.680 núcleos CUDA y 12 GB de memoria Micron GDDR6X, y con DLSS 3 es más rápida que la RTX 3090 Ti, la GPU insignia de la generación anterior. Su precio es de 899 dólares.
Otra novedad de esta GTC sep22 es que NVIDIA Lightspeed Studios utilizó Omniverse para reimaginar Portal, uno de los juegos más célebres de la historia. Con NVIDIA RTX Remix, un conjunto de herramientas asistidas por IA, los usuarios pueden modificar sus juegos favoritos, lo que les permite aumentar la resolución de las texturas y los activos, y dar a los materiales propiedades físicamente precisas.
Fuente: NVIDIA
Impulsando los avances de la IA: la GPU H100
Relacionando los sistemas y el software con las tendencias tecnológicas generales, Huang explicó que los grandes modelos de lenguaje, o LLM; y los sistemas de recomendación son los dos modelos de IA más importantes en la actualidad.
Y los grandes modelos de lenguaje basados en el modelo de deep learning Transformer, presentado por primera vez en 2017, se encuentran ahora entre las áreas más vibrantes para la investigación en IA y son capaces de aprender a entender el lenguaje humano sin supervisión o conjuntos de datos etiquetados.
Un solo modelo preentrenado puede realizar múltiples tareas, como la respuesta a preguntas, el resumen de documentos, la generación de textos, la traducción e incluso la programación de software. Hopper está en plena producción y pronto se convertirá en el motor de las fábricas de inteligencia artificial del mundo
Jensen Huang, CEO de NVIDIA.
Grace Hopper, que combina la CPU Grace para centros de datos basada en Arm con las GPU Hopper, con su capacidad de memoria rápida 7 veces mayor, supondrá un «salto de gigante» para los sistemas de recomendación. Los sistemas que incorporen Grace Hopper estarán disponibles en el primer semestre de 2023.
Tejiendo el metaverso: la GPU L4
La próxima evolución de internet, denominada metaverso, se ampliará con el 3D.
Omniverse es la plataforma de NVIDIA para crear y ejecutar aplicaciones del metaverso. La conexión y simulación de estos mundos requerirá nuevos ordenadores potentes y flexibles. Y los servidores OVX de NVIDIA están pensados para escalar estas aplicaciones. Los sistemas OVX de segunda generación de NVIDIA estarán equipados con las GPU para Ada Lovelace L40.
Thor para vehículos autónomos, robótica, instrumentos médicos y más
En los vehículos actuales, la seguridad activa, el aparcamiento, el control del conductor, las cámaras de los retrovisores, el clúster y el ordenador de a bordo son gestionados por distintos ordenadores. En el futuro, estarán a cargo de un software que mejorará con el tiempo y que se ejecutará en un ordenador centralizado.
Y en este sentido, Huang presentó DRIVE Thor, que combina el motor transformador de Hopper, la GPU de Ada y la sorprendente CPU de Grace.
El nuevo superchip Thor ofrece 2.000 teraflops de rendimiento, sustituyendo a Atlan en la hoja de ruta de DRIVE; y proporcionando una transición perfecta desde DRIVE Orin, que tiene 254 TOPS de rendimiento y se encuentra actualmente en los vehículos de producción.
Thor será el procesador para la robótica, los instrumentos médicos, la automatización industrial y los sistemas de inteligencia artificial de vanguardia.
Jensen Huang, CEO de NVIDIA.
3,5 millones de desarrolladores, 3.000 aplicaciones aceleradas
Existe un ecosistema de software con más de 3,5 millones de desarrolladores que están creando unas 3.000 aplicaciones aceleradas utilizando los 550 kits de desarrollo de software, o SDK, y los modelos de IA de NVIDIA. Y está creciendo rápidamente. En los últimos 12 meses, NVIDIA ha actualizado más de 100 SDK y ha introducido 25 nuevos.
Los nuevos SDK aumentan la capacidad y el rendimiento de los sistemas que ya poseen nuestros clientes, al tiempo que abren nuevos mercados para la computación acelerada.
Jensen Huang, CEO de NVIDIA.
Nuevos servicios para la IA y los mundos virtuales
Basados en la arquitectura de transformadores, los grandes modelos lingüísticos pueden aprender a entender significados y lenguajes sin supervisión ni conjuntos de datos etiquetados, lo que desbloquea nuevas y notables capacidades.
Para facilitar a los investigadores la aplicación de esta «increíble» tecnología, Huang anunció Nemo LLM, un servicio en la nube gestionado por NVIDIA que permite adaptar los LLM preentrenados para realizar tareas específicas. Y para acelerar el trabajo de los investigadores de fármacos y biociencia, también se anunció BioNeMo LLM, un servicio para crear LLMs que comprendan sustancias químicas, proteínas y secuencias de ADN y ARN.
Huang también detalló NVIDIA Omniverse Cloud; una infraestructura que conecta las aplicaciones Omniverse que se ejecutan en la nube, en las instalaciones o en un dispositivo.
Los nuevos contenedores de Omniverse ya están disponibles para su implantación en la nube :
Replicator. Para la generación de datos sintéticos.
Farm. Para el escalado de granjas de renderizado.
Isaac Sim. Para la construcción y el entrenamiento de robots de IA.
Omniverse está siendo adoptado e implementado por importantes compañías en todo el mundo:
Lowe’s. Tiene casi 2.000 puntos de venta, utiliza Omniverse para diseñar, construir y operar gemelos digitales de sus tiendas.
Charter, proveedor de telecomunicaciones de 50.000 millones de dólares; y HeavyAI, proveedor de análisis de datos interactivos. Están utilizando Omniverse para crear gemelos digitales de las redes 4G y 5G de Charter.
GM. está creando un gemelo digital de su estudio de diseño de Michigan en Omniverse, en el que pueden colaborar diseñadores, ingenieros y comercializadores.
Lowe’s está utilizando Omniverse para diseñar, construir y operar gemelos digitales de sus tiendas. Fuente: NVIDIA
Nuevo Jetson Orin Nano para robótica
Jensen Huang anunció también Jetson Orin Nano, un diminuto ordenador para robótica que es 80 veces más rápido que el anterior y superpopular Jetson Nano.
Jetson Orin Nano ejecuta la pila de robótica NVIDIA Isaac y presenta el marco acelerado por GPU ROS 2, y NVIDIA Iaaac Sim, una plataforma de simulación de robótica.
Nuevas herramientas para servicios de vídeo e imagen
La mayor parte del tráfico mundial de Internet es vídeo, y los flujos de vídeo generados por los usuarios se verán cada vez más aumentados por efectos especiales de IA y gráficos por ordenador, explicó Huang.
Los avatares se encargarán de la visión por ordenador, la inteligencia artificial del habla, la comprensión del lenguaje y los gráficos por ordenador en tiempo real y a escala de la nube
Jensen Huang, CEO de NVIDIA.
Para posibilitar nuevas innovaciones en la intersección de los gráficos en tiempo real, la IA y las comunicaciones, Huang anunció que NVIDIA ha estado creando librerías de aceleración como CV-CUDA, un motor de ejecución en la nube llamado UCF Unified Computing Framework, Omniverse ACE Avatar Cloud Engine y una aplicación de muestra llamada Tokkio para avatares de atención al cliente (chatbots).
GTC sep22: esto es solo el comienzo
En la GTC sep22 hemos anunciado nuevos chips, nuevos avances en nuestras plataformas y, por primera vez, nuevos servicios en la nube. Estas plataformas impulsan nuevos avances en IA, nuevas aplicaciones de IA y la próxima ola de IA para la ciencia y la industria
Edge Computing es la práctica de procesar los datos físicamente más cerca de su origen.
Fuente: NVIDIA
Smart cities. Cirugías a distancia. Vehículos totalmente autónomos. altavoces domésticos controlados por voz… Todas estas tecnologías innovadoras son posibles gracias al edge computing.
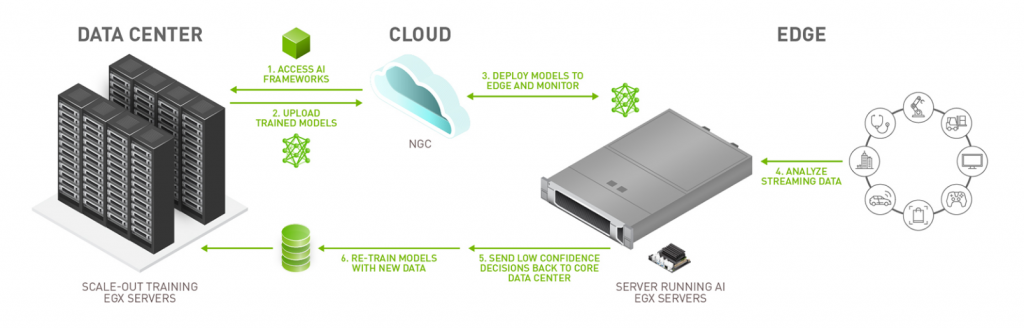
¿Qué es edge computing?
Edge Computing (traducido a español sería algo así como computación de borde o perimentral) es la práctica de trasladar la potencia de cálculo físicamente más cerca del lugar donde se generan los datos; normalmente, un dispositivo o sensor de IoT. Se denomina así por la forma en que la potencia de cálculo se lleva al «borde», al «extremo», al «límite» de un dispositivo o red. Edge computing se utiliza para procesar los datos más rápidamente, aumentar el ancho de banda y garantizar la autonomía de los datos.
Fuente: NVIDIA
Al procesar los datos en el extremo de la red, edge computing reduce la necesidad de que grandes cantidades de datos viajen entre los servidores, la nube y los dispositivos o ubicaciones de borde. Esto resuelve los problemas de infraestructura que se encuentran en el procesamiento de datos convencional, como la latencia y el ancho de banda. Esto es especialmente importante para aplicaciones modernas como la ciencia de datos y la inteligencia artificial.
Casos de uso
Por ejemplo, los equipos industriales avanzados cuentan cada vez con más sensores inteligentes alimentados por procesadores con capacidad de IA que pueden hacer inferencias en el borde (edge AI). Estos sensores vigilan los equipos y la maquinaria cercana para alertar a los supervisores de cualquier anomalía que pueda poner en peligro la seguridad, la continuidad y la eficacia de las operaciones. En este caso de uso, el hecho de que los procesadores de IA estén físicamente presentes en el emplazamiento industrial, da lugar a una menor latencia y que los equipos industriales reaccionen más rápidamente a su entorno.
La retroalimentación instantánea que ofrece edge computing es especialmente crítica para las aplicaciones en las que la seguridad humana es un factor importante; como ocurre con los coches autónomos, donde el ahorro de milisegundos de procesamiento de datos y tiempos de respuesta puede ser clave para evitar accidentes. O en los hospitales, donde los médicos dependen de datos precisos y en tiempo real para tratar a sus pacientes.
Edge computing puede utilizarse en todos los lugares en los que lo sensores recogen datos; desde tiendas de venta al por menor y hospitales para cirugías a distancia, hasta almacenes con una logística inteligente de la cadena de suministro y fábricas con inspecciones de control de calidad.
¿Cómo funciona edge computing?
Edge computing funciona procesando los datos lo más cerca posible de su fuente o usuario final. Mantiene los datos, las aplicaciones y la potencia de cálculo lejos de una red o un centro de datos centralizados.
Tradicionalmente, los datos producidos por los sensores suelen ser revisados manualmente por humanos, se dejan sin procesar o se envían a la nube o a un data center para ser procesados y luego devueltos al dispositivo. Confiar únicamente en las revisiones manuales da lugar a procesos más lentos y menos eficientes. La computación en la nube proporciona recursos informáticos; sin embargo, el viaje y el procesamiento de los datos suponen una gran carga para el ancho de banda y la latencia.
Ancho de banda y latencia
El ancho de banda es la velocidad a la que se transfieren los datos por Internet. Cuando los datos se envían a la nube viajan a través de una red de área amplia, que puede ser muy cara debido a su cobertura global y a las elevadas necesidades de ancho de banda. Cuando los datos se procesan en el borde, se pueden utilizar redes de área local, lo que supone un mayor ancho de banda con menores costes.
La latencia es el retraso en el envío de información de un punto a otro. Se reduce cuando se procesa en el borde, porque los datos producidos por los sensores y dispositivos IoT ya no necesitan enviar datos a una nube centralizada para ser procesados. Incluso en las redes de fibra óptica más rápidas, los datos no pueden viajar más rápido que la velocidad de la luz.
Al llevar a cabo edge computing se reduce la latencia y se incrementa el ancho de banda, lo que da como resultado información y acciones más rápidas.
Fuente: NVIDIA
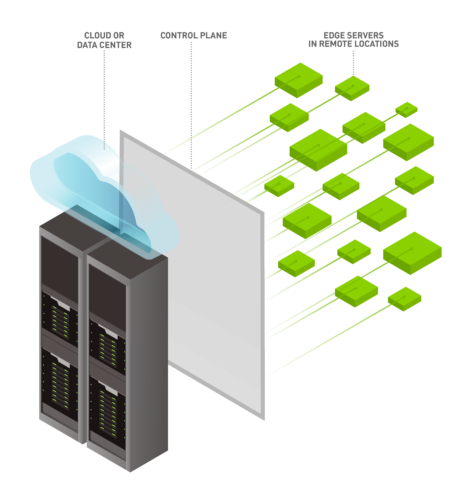
Edge computing puede ejecutarse en uno o varios sistemas para acortar la distancia entre el lugar donde se recogen y procesan los datos, reducir los cuellos de botella y acelerar las aplicaciones. Una infraestructura de borde ideal también implica una plataforma de software centralizada que pueda gestionar de forma remota todos los sistemas de borde en una sola interfaz.
¿Por qué es necesaria esta técnica computacional?
Hoy en día, tres tendencias tecnológicas están convergiendo y creando casos de uso que requieren que las organizaciones consideren edge computing: IoT, IA y 5G.
IoT
Con la proliferación de dispositivos IoT llegó la expansión de big data que empezaron a generar las empreas. A medida que las organizaciones aprovechaban la recopilación de datos de todos los aspectos de sus negocios, se dieron cuenta de que sus aplicaciones no estaban construidas para manejar tales volúmenes de datos.
Además, se percataron de que la infraestructura para transferir, almacenar y procesar todos estos datos era extremadamente cara y difícil de gestionar. Esta puede ser la razón por la que solo se procesa una parte de los datos recopilados de los dispositivos IoT (25% en algunos casos).
Y el problema se agrava aún más. En la actualidad hay 40.000 millones de dispositivos IoT y las predicciones indican que podrían aumentar al billón en 2022. A medida que crece el número de dispositivos IoT y aumenta la cantidad de datos que hay que transferir, almacenar y procesar, las organizaciones recurren más a edge computing para reducir los costes necesarios para utilizar los mismos datos en los modelos de computación en la nube.
IA
La IA representa un sinfín de posibilidades y beneficios para las empresas, como la capacidad de obtener información en tiempo real. Las empresas están descubriendo que su infraestructura de nube actual no puede cumplir con los requisitos que requieren los nuevos casos de uso para la IA.
Cuando las organizaciones tienen limitaciones de ancho de banda y latencia, tienen que recortar la cantidad de datos que alimentan a sus modelos. Y esto da lugar a modelos más débiles.
5G
Las redes 5G, diez veces más rápidas que las 4G, están construidas para permitir que cada nodo sirva a cientos de dispositivos; aumentando así las posibilidades de los servicios habilitados por la IA en las ubicaciones de borde.
Con la potente, rápida y fiable capacidad de procesamiento de edge computing, las empresas pueden explorar nuevas oportunidades de negocio, obtener información en tiempo real, aumentar la eficiencia operativa y mejorar la experiencia del usuario.
¿Cuáles son los beneficios de edge computing?
Menor latencia. Al procesar en el borde de una red, se reducen o eliminan los viajes de datos, lo que acelera la IA. Esto abre la puerta a casos de uso con modelos de IA más complejos, como los vehículos autónomos y la realidad aumentada.
Reducción de costes. El uso de una LAN para el procesamiento de datos significa que las organizaciones pueden acceder a un mayor ancho de banda y almacenamiento a un menor coste que con la computación en la nube. Además, como el procesamiento se realiza en el borde, no es necesario enviar tantos datos a la nube o al data center para su procesamiento posterior.
Precisión de los modelos. La IA se basa en modelos de alta precisión, especialmente para los casos de uso que requieren respuestas instantáneas. Cuando el ancho de banda de una red es demasiado bajo, se soluciona reduciendo el tamaño de los datos utilizados para la inferencia. Esto suele dar como resultado imágenes reducidas, fotogramas omitidos en vídeo y frecuencias de muestreo reducidas en audio. Cuando se despliega en el borde, los bucles de retroalimentación de datos pueden utilizarse para mejorar la precisión del modelo de IA y se pueden ejecutar varios modelos simultáneamente, lo que da lugar a una mejor comprensión de los mismos.
Mayor alcance. Internet es necesario para la computación en la nube; pero con edge computing los datos se procesan sin acceso a internet, lo que amplía su alcance a lugares anteriormente inaccesibles.
Autonomía de los datos. Cuando los datos se procesan en el lugar donde se recogen, las organizaciones pueden mantenerlos dentro de la LAN y el firewall de la empresa. Esto se traduce en una menor exposición a los ataques de ciberseguridad de la nube y a las estrictas y cambiantes leyes de protección de datos.
Casos de uso en todas las industrias
Edge computing puede aportar inteligencia en tiempo real a las empresas de todos los sectores.
Fuente: NVIDIA
Comercio minorista
Ante la rápida evolución de la demanda, el comportamiento y las expectativas de los consumidores, los minoristas más grandes del mundo recurren a la IA avanzada para ofrecer mejores experiencias a los usuarios.
Con edge computing los minoristas pueden aumentar su agilidad mediante:
Reducción de las pérdidas. Con cámaras y sensores inteligentes en los comercios que aprovecha edge computing para analizar datos, se pueden identificar y prevenir casos de errores, desperdicios, daños y robos.
Mejora de la gestión del inventario. Las aplicaciones de edge computing pueden utilizar cámaras para alertar cuándo baja el stock, evitando así las posibles roturas.
Optimización de la experiencia de compra. Con el rápido procesamiento de datos de edge computing, los minoristas pueden implementar pedidos por voz para que los compradores puedan buscar fácilmente artículos, pedir información sobre productos y hacer pedidos online utilizando altavoces u otros dispositivos inteligentes.
Smart cities
Ciudades, campus universitarios, estadios y centros comerciales son algunos ejemplos de lugares que han empezado a utilizar la IA para transformarse en espacios inteligentes. Esto se traduce en una mayor eficiencia desde el punto de vista operativo, seguridad y accesibilidad.
Edge computing se ha utilizado para transformar las operaciones y mejorar la seguridad en todo el mundo en áreas como:
Reducción de la congestión del tráfico. Las ciudades utilizan computer vision para identificar, analizar y optimizar el tráfico; disminuir los costes relacionados con los atascos; y minimizar el tiempo que los conductores pasan en el vehículo.
Supervisión de la seguridad en las playas. Detectar los posibles peligros en las playas, como la resaca, las corrientes y las condiciones peligrosas del mar, permite a las autoridades poner en marcha procedimientos para salvar vidas.
Aumento de la eficiencia de las operaciones de las aerolíneas y los aeropuertos. Una aplicación de análisis de vídeo con IA ayuda a las aerolíneas y los aeropuertos a tomar mejores decisiones de forma más rápida en cuanto a capacidad, sostenibilidad y seguridad.
Industria
Las fábricas y las empresas automovilísticas están generando datos de sensores que pueden utilizarse de forma cruzada para mejorar los servicios. Algunos casos de uso para promover la eficiencia y la productividad en la fabricación son:
Mantenimiento predictivo: Detección temprana de anomalías y predicción de cuándo van a fallar las máquinas para evitar tiempos de inactividad.
Control de calidad. Detectar defectos en los productos y alertar al personal al instante para reducir los residuos y mejorar la eficiencia de la fabricación.
Seguridad de los trabajadores. Uso de una red de cámaras y sensores equipados con análisis de vídeo con IA para que los fabricantes puedan identificar a los trabajadores en condiciones inseguras e intervenir rápidamente para evitar accidentes.
Sanidad
La combinación de edge computing e IA está transformando la atención sanitaria. La IA «en el borde» proporciona a los trabajadores sanitarios las herramientas que necesitan para mejorar la eficiencia operativa, garantizar la seguridad y ofrecer una experiencia asistencial de la mayor calidad posible.
Dos ejemplos muy claros de edge computing en este sector son:
Los quirófanos. Los modelos de IA construidos sobre imágenes en streaming y sensores en dispositivos médicos están ayudando a:
La adquisición y reconstrucción de imágenes.
La optimización del flujo de trabajo para el diagnóstico y la planificación de la terapia.
La medición de órganos y tumores.
La orientación de la terapia quirúrgica.
La visualización y monitorización en tiempo real durante las cirugías.
Los hospitales. Los hospitales inteligentes están utilizando tecnologías como la monitorización de pacientes, la detección de enfermedades, la IA conversacional, la estimación de la frecuencia cardíaca, los escáneres radiológicos, etc. Utilizando computer vision se puede ayudar a notificar al personal sanitario cuándo un paciente se mueve o se cae de una cama del hospital.
El futuro de edge computing
La capacidad de obtener información más rápida puede suponer un ahorro de tiempo, costes e incluso vidas. Por ello, las empresas están aprovechando los datos generados por los miles de millones de sensores de IoT que se encuentran en las tiendas, en las calles de las ciudades y en los hospitales para crear espacios inteligentes.
Pero para ello, las organizaciones necesitan sistemas de edge computing que ofrezcan una computación potente y distribuida, una gestión remota segura y sencilla y compatibilidad con las tecnologías líderes del sector.
El mercado de edge computing tendrá un valor de 251.000 millones de dólares en 2025, y se espera que siga creciendo cada año con una tasa de crecimiento anual del 16,4%.
La evolución de la IA, el IoT y el 5G seguirá catalizando la adopción de edge computing. El número de casos de uso y los tipos de cargas de trabajo desplegados «en el borde» crecerán. En la actualidad, los casos de uso más frecuentes giran en torno a computer vision. Sin embargo, hay muchas oportunidades sin explorar en áreas de trabajo como el procesamiento del lenguaje natural, los sistemas de recomendación y la robótica.
Las posibilidades «en el borde» son realmente ilimitadas.
El superordenador de IA de Meta, el mayor sistema para clientes de NVIDIA DGX A100 hasta la fecha, proporcionará a los investigadores de «Meta AI» 5 exaflops de rendimiento de IA y cuenta con sistemas NVIDIA de última generación, tejido InfiniBand y software que permite la optimización en miles de GPU.
«Meta Platforms» ha elegido las tecnologías de NVIDIA para lo que cree que será su sistema de investigación más potente hasta la fecha.
Fuente: NVIDIA
El AI Research SuperCluster (RSC) ya está entrenando nuevos modelos para avanzar en la IA. Una vez desplegado por completo, se espera que el RSC de Meta sea la mayor instalación de sistemas NVIDIA DGX A100 de un cliente.
«Esperamos que el RSC nos ayude a crear sistemas de IA totalmente nuevos que puedan, por ejemplo, realizar traducciones de voz en tiempo real a grandes grupos de personas, cada una de las cuales habla un idioma diferente, para que puedan colaborar sin problemas en un proyecto de investigación o jugar juntos a un juego de realidad aumentada».
Cuando el RSC esté completamente construido, a finales de año, Meta pretende utilizarlo para entrenar modelos de IA con más de un billón de parámetros. Esto podría suponer un avance en campos como el procesamiento del lenguaje natural para tareas como la identificación de contenidos nocivos en tiempo real.
Además del rendimiento a escala, Meta aboga por la fiabilidad extrema, la seguridad, la privacidad y la flexibilidad para manejar una amplia gama de modelos de IA como sus criterios clave para RSC.
El superclúster de investigación de IA de Meta cuenta con cientos de sistemas NVIDIA DGX conectados a una red NVIDIA Quantum InfiniBand para acelerar el trabajo de sus equipos de investigación de IA.
La infraestructura de Meta
El nuevo superordenador de IA utiliza actualmente 760 sistemas NVIDIA DGX A100 como nodos de cálculo. Estos sistemas cuentan con un total de 6.080 GPU NVIDIA A100 conectadas a una red InfiniBand NVIDIA Quantum de 200 Gb/s para ofrecer 1.895 petaflops de rendimiento TF32.
A pesar de los desafíos de COVID-19, RSC tardó solo 18 meses en pasar de ser una idea sobre el papel a un superordenador de IA en funcionamiento; gracias, en parte, a la tecnología NVIDIA DGX A100 en la base de Meta RSC.
Penguin Computing es el socio de NVIDIA Partner Network para RSC. Además de los 760 sistemas DGX A100 y la red InfiniBand, Penguin proporciona servicios gestionados e infraestructura optimizada para la IA de Meta; compuesta por 46 petabytes de almacenamiento en caché con sus sistemas Altus. Pure storage FlasBlade y FlasArray//C proporcionan las capacidades de almacenamiento all-flash de alto rendimiento y escalabilidad necesarias para impulsar el RSC.
Aumento del rendimiento x20
Es la segunda vez que Meta elige las tecnologías de NVIDIA como base de su infraestructura de investigación. En 2017, Meta construyó la primera generación de dicha infraestructura de IA con 22.000 GPUs NVIDIA V100 Tensor Core que manejan 35.000 trabajos de entrenamiento de IA al día.
Las primeras pruebas de Meta mostraron que RSC puede entrenar grandes modelos de PNL 3 veces más rápido y ejecutar trabajos de visión por ordenador 20 veces más rápido que el sistema anterior.
En una segunda fase, a finales de año, RSC ampliará a 16.000 GPUs que proporcionarán 5 exaflops de rendimiento de IA de precisión mixta. Además, Meta pretende ampliar el sistema de almacenamiento de RSC para ofrecer hasta un exabyte de datos a 16 terabytes por segundo.
Una arquitectura escalable
Las tecnologías de IA de NVIDIA están disponibles para empresas de cualquier tamaño.